Streamscope Continuous Reliable Distributed Processing of Big Data Streams Paper Review
StreamScope: Continuous Reliable Distributed Processing of Big Data Streams – Lin et al. NSDI '16
An emerging trend in big data processing is to extract timely insights from continuous big data streams with distributed computation running on a large cluster of machines. Examples of such data streams include those from sensors, mobile devices, and on-line social media such as Twitter and Facebook.
We've previously looked at a number of streaming systems in The Morning Paper including Google Cloud Dataflow, MillWheel, Spark Streaming, Twitter Storm and Heron, Liquid, Naiad, and Apache Flink. StreamScope is Microsoft's production streaming system, deployed on 20,000-server production clusters where it processes tens of billions of events per day with complex computation logic. One use case for StreamScope at Microsoft is the detection of fraud clicks in on-line advertising, with refunds generated for affected customers. Strong guarantees (exactly once processing of each event) are needed because the application is related to accounting, and lower latency allows customer to adjust selling strategies more quickly. This particular application involves 48 stages, 18 joins, and a huge in-memory state of around 21TB since millions of features are extracted from raw events with a large number of complex statistics being retained in-memory before being fed into an on-line prediction engine for fraud detection. It executes on 3,220 vertices and results in about 180TB of I/O per day.
A defining characteristic of cloud-scale steam computation is its ability to process potentially infinite input events continuously with delays in seconds and minutes, rather than processing a static data set in hours and days. The continuous, transient, and latency-sensitive nature of stream computation makes it challenging to cope with failures and variations that are typical in a large-scale distributed system, and makes stream applications hard to develop, debug, and deploy.
Let's take a look at how StreamScope meets those challenges…
Programming model and key abstractions
The key concepts in StreamScope, such as declarative SQL-like language, temporal relational algebra, compilation and optimization to streaming DAG, and scheduling, have been inherited from the design of stream database systems, which extensively studied stream semantics and distributed processing. StreamScope's novelty is in the new rStream and rVertex abstractions designed for high scalability and fault tolerance through decoupling, representing a different and increasingly important design point that favors scalability at the expense of somewhat loosened latency requirements.
Event streams have a well-defined schema, and every event has a time interval describing the start and end time for which the event is valid. Special Current Time Increments (CTI) events assert the completeness of event delivery up to to some time t. These guarantee there will be no events with a timestamp lower than t in the stream after them.
End users work with a declarative query language and do not have to concern themselves with details of scalability and fault tolerance directly. The query language is based on SCOPE. Consider a system with two event streams, Process events and Alert events. Process events contain information about processes and their associated users, alerts record information about alerts and the process that generated them.
We can join the process and alert streams to attach user information to alerts as follows:
AlertWithUserID = SELECT Alert.Name AS Name, Process.UserID AS UserID FROM Process INNER JOIN Alert ON Process.ProcessID == Alert.ProcessID; Using this joined stream, we can further calculate the number of alerts per user every 5 seconds:
CountAlerts = SELECT UserID, COUNT(*) AS AlertCount FROM AlertWithUserID GROUP BY UserID WITH HOPPING(5s, 5s); Projections, filters, grouping and joins are all supported, adapted for temporal semantics. A StreamScope program is converted into a logical plan (DAG) of runtime operators, and the optimizer then evaluates possible execution plans choosing the one with the lowest estimated cost. A physical plan is then created by mapping a logical vertex into an appropriate number of physical vertices for parallel execution and scaling. Computation is performed at vertices in the DAG, consuming input streams on their in-edges, and producing output stream(s) on their out-edges. A sample DAG for the alert counting example is shown below.
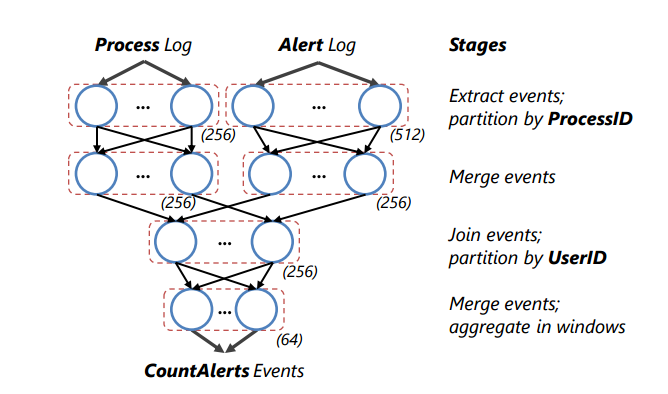
StreamScope is modeled on two key abstrations called rStreams and rVertices.
The rStream abstraction decouples upstream and downstream vertices, providing reliable channels that allow receivers to read from any written position. An rStream provides a sequence of events with monotonically increasing sequence numbers, and multiple writers and readers are supported. The implementation supports both push and pull styles. Readers can rewind streams by re-registering with an earlier sequence number. This causes the stream to be replayed from that sequence number. To support this StreamScope asynchronously flushes an in-memory buffer of events to persistent storage, in order to survive system failure.
To be able to recompute lost events [those that had not yet been flushed] in case of failures, StreamScope tracks how each event is computed, similar to dependency tracking in TimeStream or lineage in D-Streams. In particular, during execution the job manager tracks vertex snapshots which it can use later to infer how to reproduce events in the output streams.
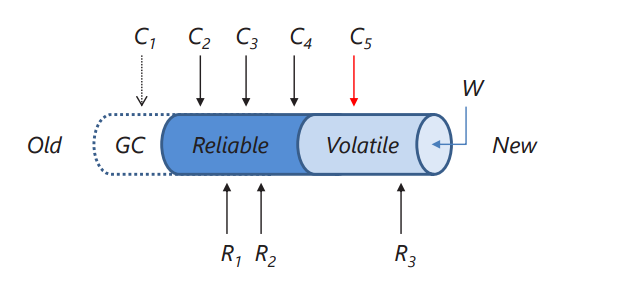
A stream is thus comprised of three logical sections: events with sequence numbers below a GC low-water mark (these cannot be recovered anymore), events that are reliably stored, and volatile events that exist only in in-memory buffers, waiting to be flushed:
The rVertex abstraction supports computation at vertices. Vertices maintain local state which is tracked through a series of snapshots, and Load(s) will start an instance of the vertex at snapshot s. Vertex execution is deterministic: for a vertex with given input streams, running Execute() on the same snapshot always causes the vertex to transition into the same new snapshot and produce the same output events. This determinism in necessary when replaying an execution during failure recovery. To ensure determinism in the ordering of events across multiple input streams, a special merge operator is inserted at the beginning of a vertex taking more than one input stream. This operator waits for corresponding Current Time Increment (CTI) events to show up in each stream, and then orders events in the streams deterministically and emits them in that order. "Because the processing logic of vertices tends to wait for the CTI events in the same way, this solution does not introduce additional noticeable delay."
Implementation details of note
Garbage collection of snapshots, streams, and other tracking information is based on low-water marks that are maintained for vertices and streams during execution.
For a stream, the low-water mark points to the lowest sequence number of the events that are needed; for a vertex, the low-water mark points to the lowest snapshot of the vertex that is needed.
Snapshots are totally ordered by the sequence numbers of their input and output streams.
Three different failure recovery strategies are supported, that can be applied at the vertex granularity:
- checkpoint-based recovery, in which a vertex recovers by loading its state from the most recent checkpoint. This method is not ideal for vertices with large internal state (which some vertices in the Microsoft applications do have).
- replay-based recovery, appropriate for vertices that have no state, or where the only state can be reconstructed from short-term memory due to windowing operators. In this model, vertices do not checkpoint state, and instead reload a window of events to rebuild state on recovery.
- replication-based recovery, in which multiple instances of the same vertex run in parallel, connected to the same input and output streams. The rStream implementation will provide deduplication automatically. "With replication, a vertex can have instances take checkpoints in turn without affecting latency observed by readers because other instances are running at a normal pace."
Comparing the implementation to D-Streams (Spark Streaming), the authors say:
Instead of supporting a continuous stream model, D-Streams models a stream computation as a series of mini-batch computations in small time intervals and leverages immutable RDDs for failure recovery. Modeling a stream computation as a series of mini-batches could be cumbersome because many stream operators, such as windowing, joins, and aggregations, maintain states to process event streams efficiently. Breaking such operations into separate mini-batch computation requires rebuilding computation state from the previous batches before processing new events in the current batch… Furthermore, D-Streams unnecessarily couples low latency and fault tolerance: a mini-batch defines the granularity at which vertex computation is triggered and therefore dictates latency, while an immutable RDD, mainly for failure recovery, is created for each mini-batch.
(Note that the main application of StreamScope discussed in the paper, on-line advertising fraud detecting has an end-to-end latency of around 20 minutes (due to window aggregations), which is well within Spark Streaming's capabilities, "with RDDs we show that we can attain sub-second end-to-end latencies.")
StreamScope in production
StreamScope has been deployed since late 2014 in shared 20,000-server production clusters, running concurrently a few hundred thousand jobs daily, including a variety of batch, interactive, machine-learning, and streaming applications.
Under load spikes or server failures, one vertex may fall behind temporarily. In this case the input events are queued (handled transparently by the rStream abstraction). The vertex is then able to catch up quickly via event batching. For permanent increases in load (e.g. a steady increase over time) StreamScope can move to a new configuration taking advantage of snapshots to load the state of the new vertex instances.
We decided not to support dynamic reconfiguration as the additional complexity was not justified.
For planned maintenance, StreamScope uses duplicate execution of affected vertices, scheduling another instance in a safe machine. Once the new instance catches up with event processing, the affected vertex can be safely killed and maintenance can proceed.
With enough instances, stragglers are inevitable (The Tail at Scale).
Preventing and mitigating stragglers is particularly important for streaming applications where stragglers can have more severe and long-lasting performance impact. First, StreamScope continuously monitors machine health and only considers healthy machines for running streaming vertices. This significantly reduces the likelihood of introducing stragglers at runtime. Second, for each vertex, StreamScope tracks its resulting CTI events, normalized by the number of its input events, to estimate roughly its progress. If one vertex has a processing speed that is significantly slower than the others in the same stage that execute the same query logic, a duplicate copy is started from the most recent checkpoint. They execute in parallel until either one catches up with the others, at which point the slower one is killed.
Sometimes it is something particular to a rare input event which causes a vertex to appear slow – this problem cannot be fixed by duplicate execution. StreamScope has both an alerting mechanism to warn users of such situations, and also the ability to add a filter at runtime to weed out such events, pending deployment of a new version of the streaming application that can handle them more appropriately.
Source: https://blog.acolyer.org/2016/05/24/streamscope-continuous-reliable-distributed-processing-of-big-data-streams/
0 Response to "Streamscope Continuous Reliable Distributed Processing of Big Data Streams Paper Review"
Post a Comment